DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
快速上手步骤
1.下载 DataX
2.配置任务 Json
下载的 DataX 的目录:
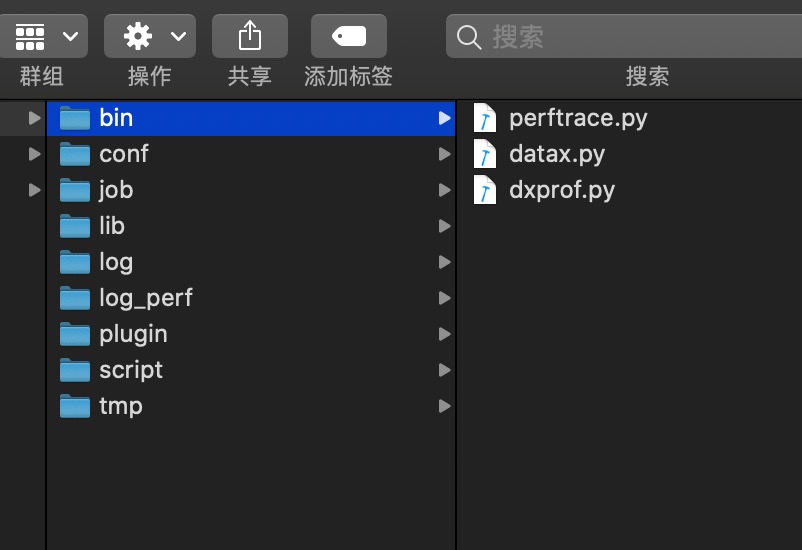
配置 datax/job 文件夹下的 Json:
|
|
任务 Json 由三部分组成,分别是读,写和通用配置。
Reader 部分常用参数:
| 参数名 | 解释 | 备注 |
|---|---|---|
| name | 与要读取的数据库一致 | 字符串 |
| jdbcUrl | 数据库链接 | 数组,会自动选择一个合法的链接,可以填写连接附件控制信息 |
| username | 数据库用户名 | 字符串,数据库的用户名 |
| password | 数据库密码 | 字符串,数据库的密码 |
| table | 要同步的表名 | 数组,需保证表结构一致 |
| column | 要同步的列名 | 数组 |
| where | 选取的条件 | 字符串 |
| querySql | 自定义查询语句 | 会自动忽略上述的同步条件 |
Writer 部分常用参数:
| 参数名 | 解释 | 备注 |
|---|---|---|
| name | 与要读取的数据库一致 | 字符串 |
| jdbcUrl | 数据库链接 | 字符串,可以填写连接附件控制信息 |
| username | 数据库用户名 | 字符串,数据库的用户名 |
| password | 数据库密码 | 字符串,数据库的密码 |
| table | 要同步的表名 | 数组,需保证表结构一致 |
| column | 列名可以不对应,但是类型和总的个数要一致 | 数组,需保证表结构一致 |
| preSql | 写入前执行的语句 | 数组,比如清空表等 |
| postSql | 写入后执行的语句 | 数组 |
| writeMode | 写入方式,默认为insert | insert/replace/update |
- job.setting.speed (流量控制)
- Job 支持用户对速度的自定义控制,channel 的值可以控制同步时的并发数,byte 的值可以控制同步时的速度
- job.setting.errorLimit (脏数据控制)
- Job 支持用户对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值(record 值)或者脏数据占比阈值(percentage 值),当 Job 传输过程出现的脏数据大于用户指定的数量/百分比,DataX Job 报错退出。
命令行 cd 到 datax/bin 目录下,执行 python datax.py ../job/mysqltomysql.json:
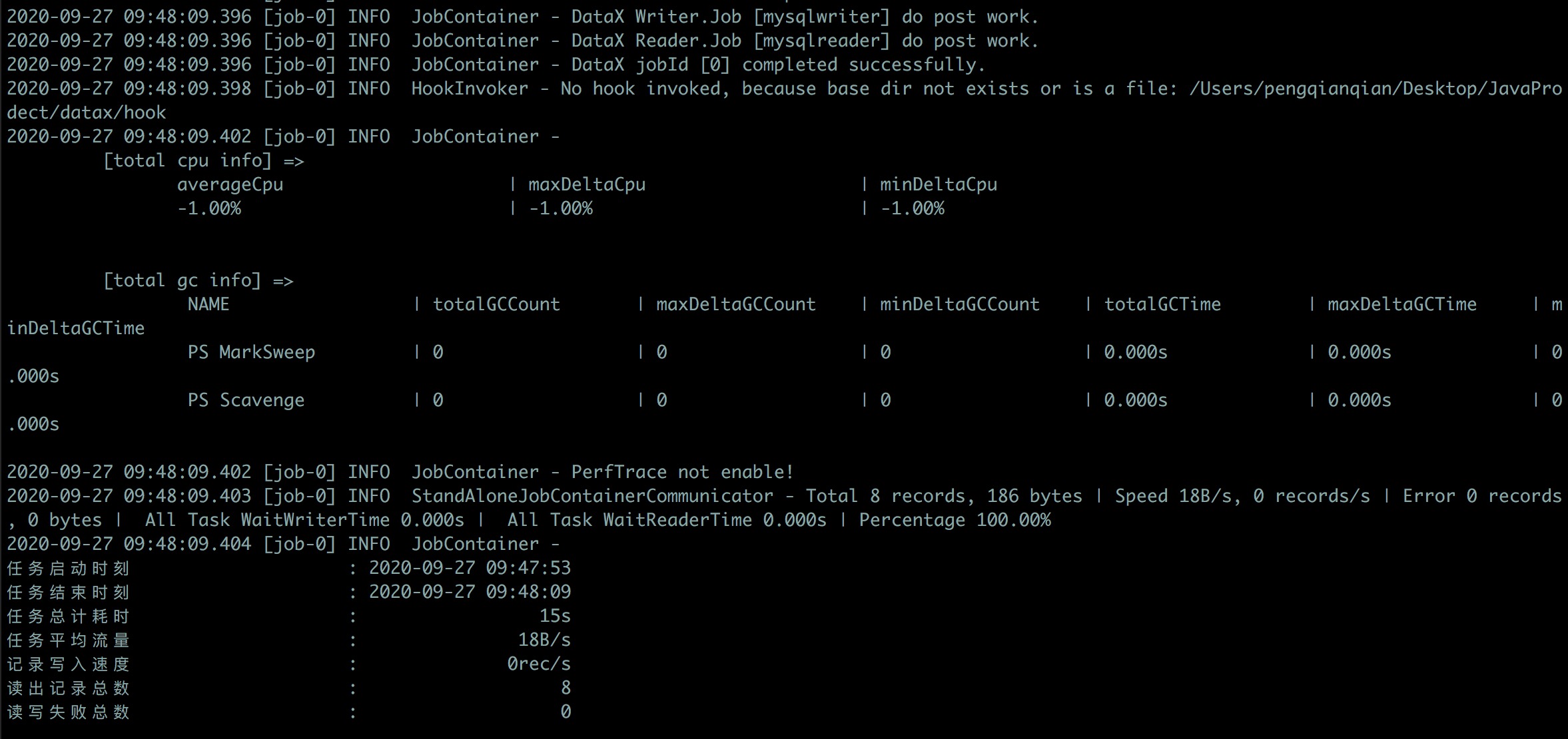
然后看到 school_test 表的数据:
到此已经成功了。