一、前言
最近在数据开发中,使用到了 Fluentd,具体情况是:移动端上传到 OSS 的日志文件,每个文件大概几 k,但有上千万之多,导致 MaxCompute 在运行的时候报内存栈溢出的错误,因此我们使用了 Fluentd,主要做的是小文件合并操作(MaxCompute 自带的文件合并无法处理)。
合并策略:OSS - Fluentd - OSS,先从 OSS 获取数据(小文件),Fluentd 进行合并之后,再重新上传至 OSS,MaxCompute 把 Fluentd 合并之后的文件当作数据源,问题解决。
二、Fluentd 简介
Fluentd 是一个开源的数据收集器,它允许统一进行数据的收集和使用,以便更好地使用以及理解数据。
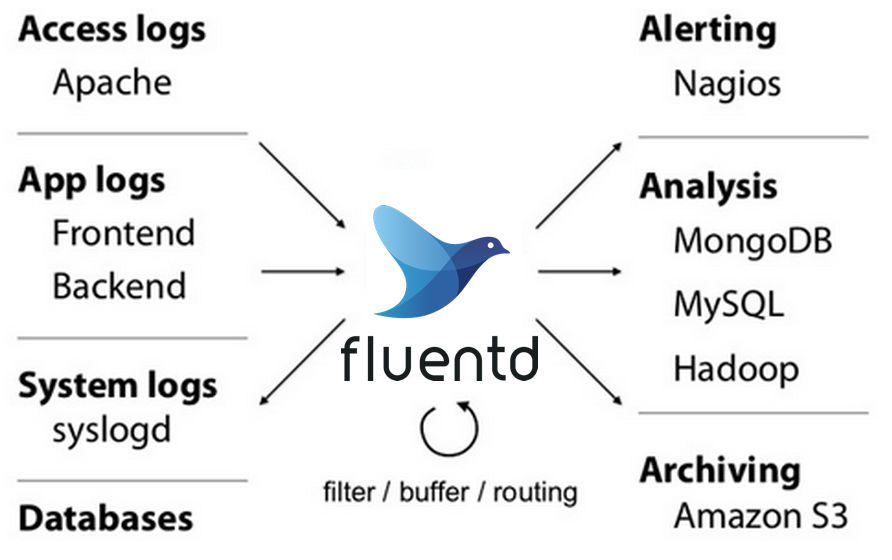
Fluentd 架构图(来自 Fluentd 官网):
三、Fluentd 集成
Fluentd 集成很简单,下载其商业化应用 td-agent,下载地址:https://docs.fluentd.org/installation。
接着安装 Fluentd 的 OSS 插件:
1
|
/usr/sbin/td-agent-gem install fluent-plugin-aliyun-oss
|
四、Fluentd 配置
1. 从 OSS 读数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
<source>
@type oss
tag load
endpoint oss-cn-hangzhou-internal.aliyuncs.com # endpoint 可以在阿里云查看
bucket *** # 桶名
access_key_id *** # 你的access_key_id
access_key_secret *** # 你的access_key_secret
flush_batch_lines 10000
store_as text
#pos_file /var/log/apache2/access_log.pos
<mns> # 监听的mns
endpoint 20967412.mns.cn-hangzhou-internal.aliyuncs.com # endpoint 可以在阿里云查看
queue *** # 监听的mns队列名称
wait_seconds 0 # 等待时间
poll_interval_seconds 0
</mns>
#<parse>
# @type json
#</parse>
</source>
|
从 OSS 读数据,需要配合阿里云的 MNS 以及 OSS 的事件通知来做,具体看文档配置事件通知。
2. 向 OSS 写数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
<match load>
@type oss
endpoint oss-cn-hangzhou-internal.aliyuncs.com # endpoint 可以在阿里云查看
bucket *** # 桶名
access_key_id *** # 你的access_key_id
access_key_secret *** # 你的access_key_secret
upload_crc_enable false
path *** # 上传到哪个文件夹下
auto_create_bucket true
store_as text
time_slice_format %Y%m%d
key_format "%{path}/%{time_slice}/aliyun_events_%{index}_%{thread_id}_1.%{file_extension}" # 合并后的文件名字
<buffer tag,time>
@type memory
path /septnet/fluentd_buf/oss-log-fluent.log
timekey 1800 # 多久上传一次,单位s
timekey_wait 1
flush_thread_count 5
#flush_interval 60s
#total_limit_size 2m
chunk_limit_size 100m
</buffer>
#<format>
# @type json
#</format>
</match>
|
-
2020.02.18 补充
-
2020.03.25 补充:
- 最近我们部门测试组在测试 Fluentd 日志合并时,出现了这样一个问题:在日志量特别大的情况下,Fluentd 会进行重复合并,比如原始日志有 10000 条,Fluentd 合并后会有 10200 条,其中 200 条是二次或多次重复合并导致的。为什么会出现这样的问题呢?这其实是由 Fluentd 自身的机制引起的。Fluentd 是日志事件交付系统,主要做的是日志不丢,因此它默认使用的是 At least once,即每条消息至少交付一次。具体文档可参考这里:High Availability Config。那么该怎么解决这个问题呢?我这边做的比较简单粗暴,但目前看也是唯一切实可行的,就是在数仓直接把重复日志过滤掉。
参考文档
fluentd 官方文档
fluentd社区
fluent-plugin-oss
fluentd简介
Fluentd性能优化实践